Understanding Merkle pollards
· Jim McDonald · 7 minutes read · 1368 words ·Merkle trees are used in the world of cryptocurrencies as an efficient way to prove the existence of a particular value within a large set of values and with minimal storage. This article introduces Merkle trees and shows how repeated proofs against the same tree can be reduced in size significantly by storing multiple levels of branches rather than just the root (known as Merkle pollards).
Hashes
A hash function turns a variable-size piece of data (in this case the name of a fruit) in to a fixed-size value (known as a hash). An example showing hashes of “Apple” and “Orange” are shown below:

Figure 1: Hashing values
Hash functions have various features, but the most important ones are that even slightly different values result in very different hashes, and that it is mathematically very hard to go from the hash back to the value (usually meaning there is no faster method than guessing a value, hashing it and seeing if it matches).
Merkle trees
A Merkle tree is a way of combining multiple values and their hashes to reduce them to a single fixed-size value.
At the top of the tree are the values, known as leaves. Each leaf is hashed to create a top-level branch, and adjacent branches are hashed together to create the intermediate branches. Eventually this will result in a single hash, known as the Merkle root. A graphical example of a Merkle tree is shown below:
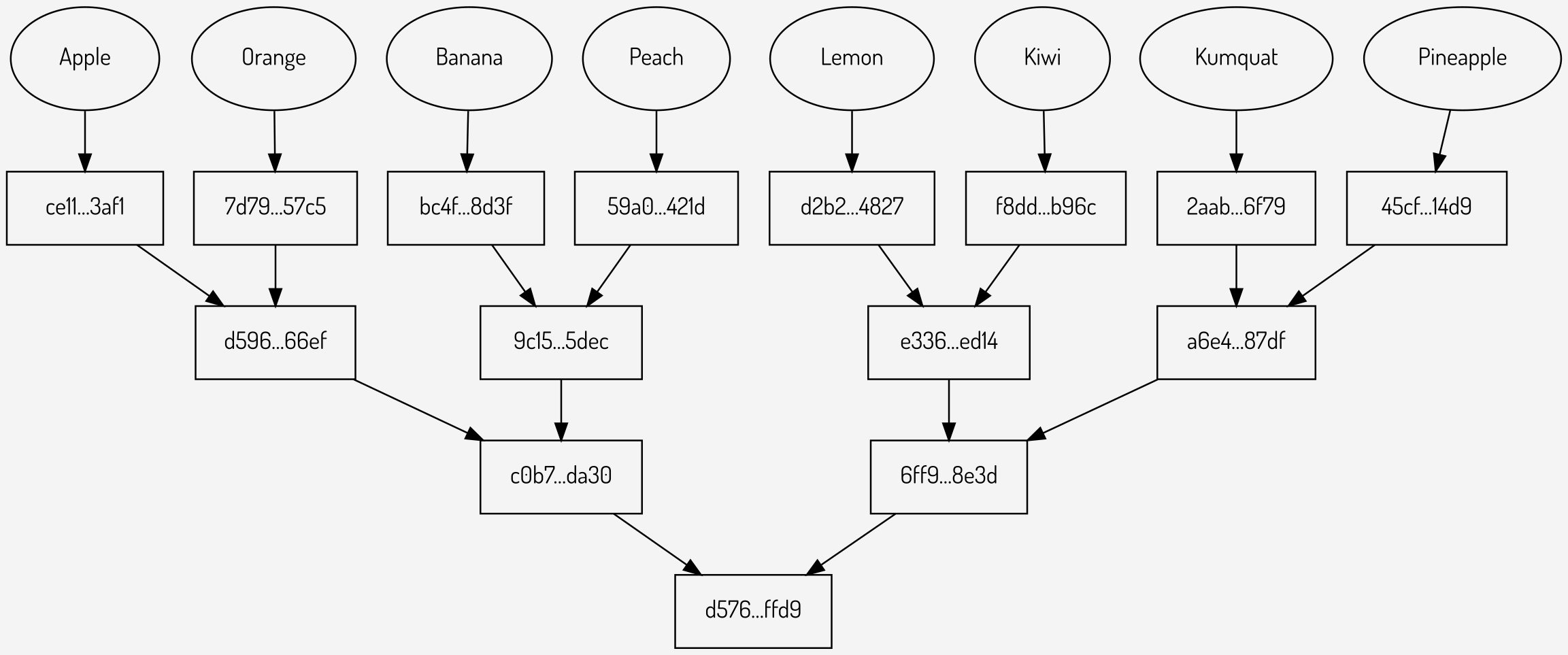
Figure 2: A Merkle tree
The above example shows a Merkle tree with 8 values and 4 levels; the root is at the bottom labelled \(d576…ffd9\).
As mentioned previously, even slightly different values will generate very different hashes. This change has a subsequent impact on all levels of the tree and will ultimately give a different root. For example, changing the single value “Peach” to “Pear” results in an altered Merkle tree as seen below:
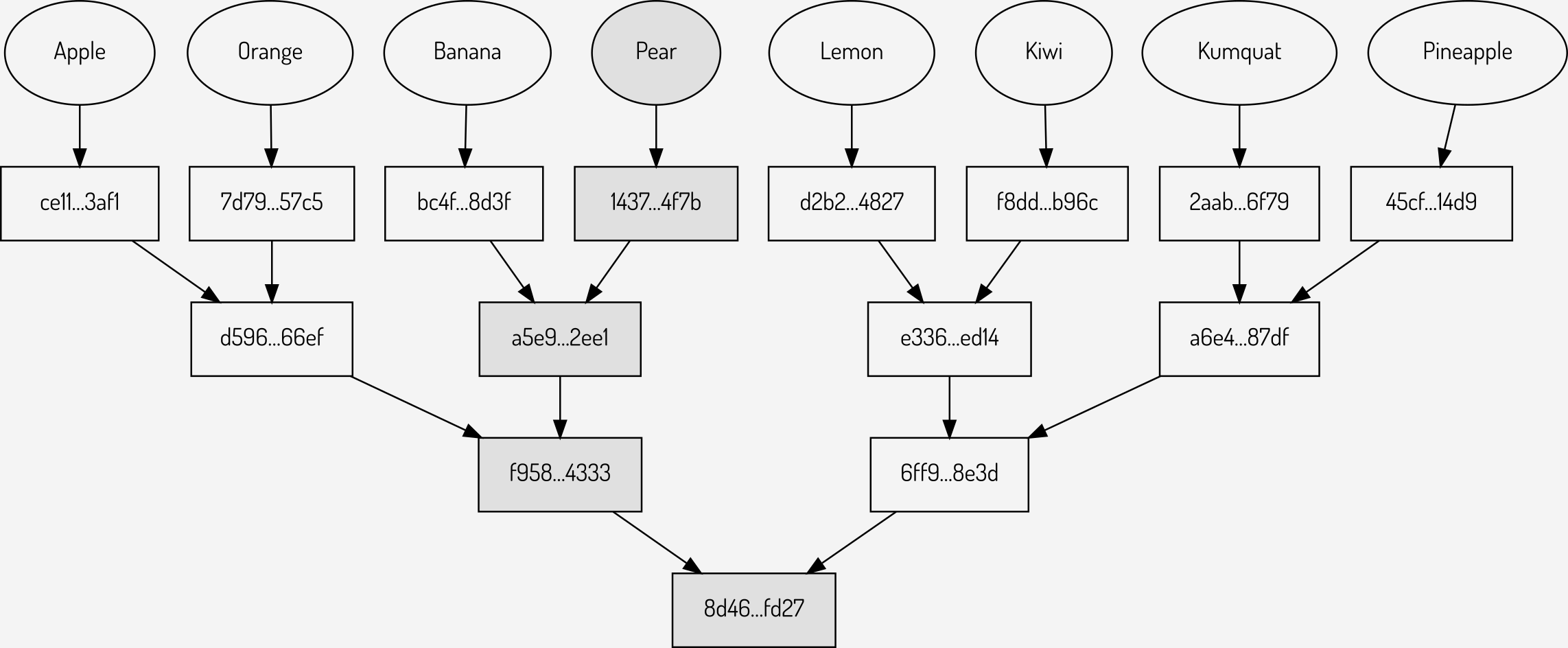
Figure 3: The impact of a single change to the tree (shown in grey)
Merkle trees are reproducible: given the same values in the same order a Merkle tree will always have the same hashes for the branches and root.
Merkle paths
The Merkle path is simply the set of hashes from the value to the Merkle root. The example below shows the Merkle path for the value “Peach”:
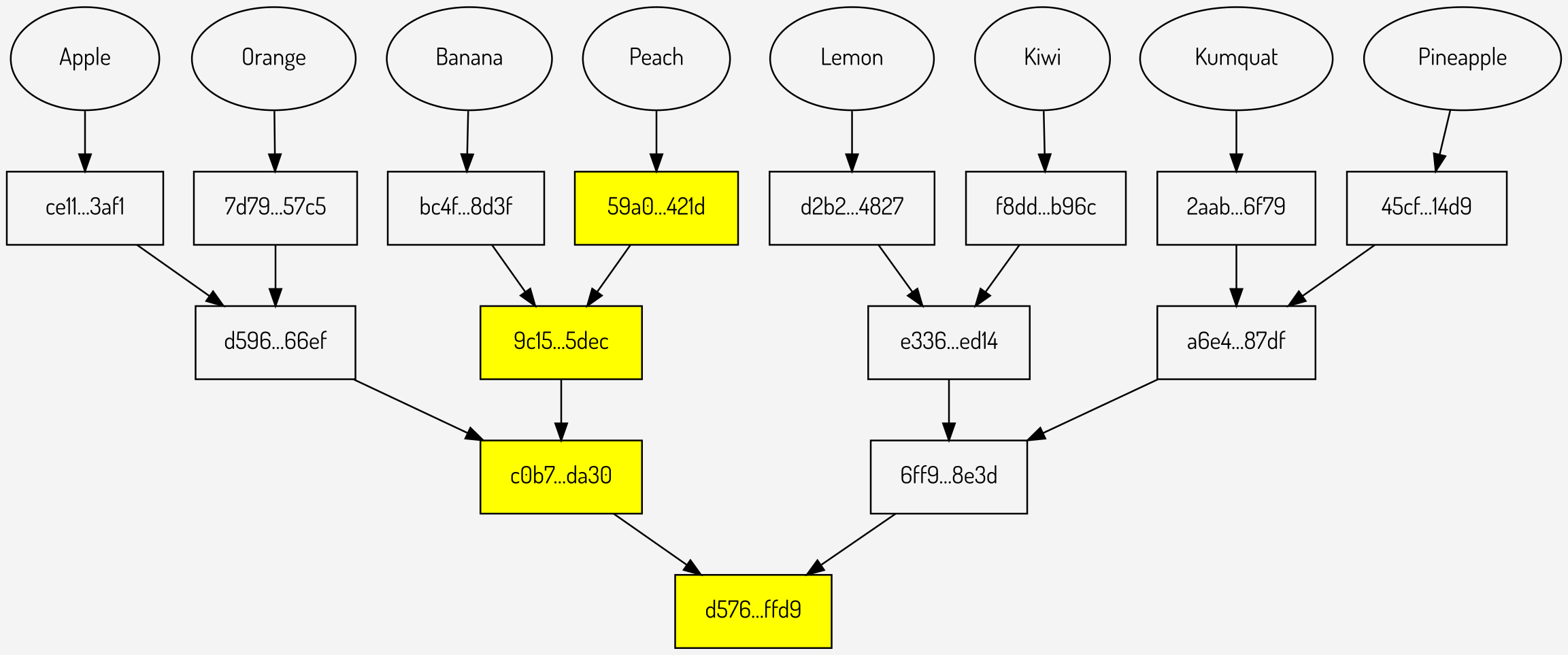
Figure 4: The Merkle path for “Peach”
Merkle proofs
A Merkle proof is a way of proving that a certain value is part of a set of data without requiring any of the other values to be exposed.
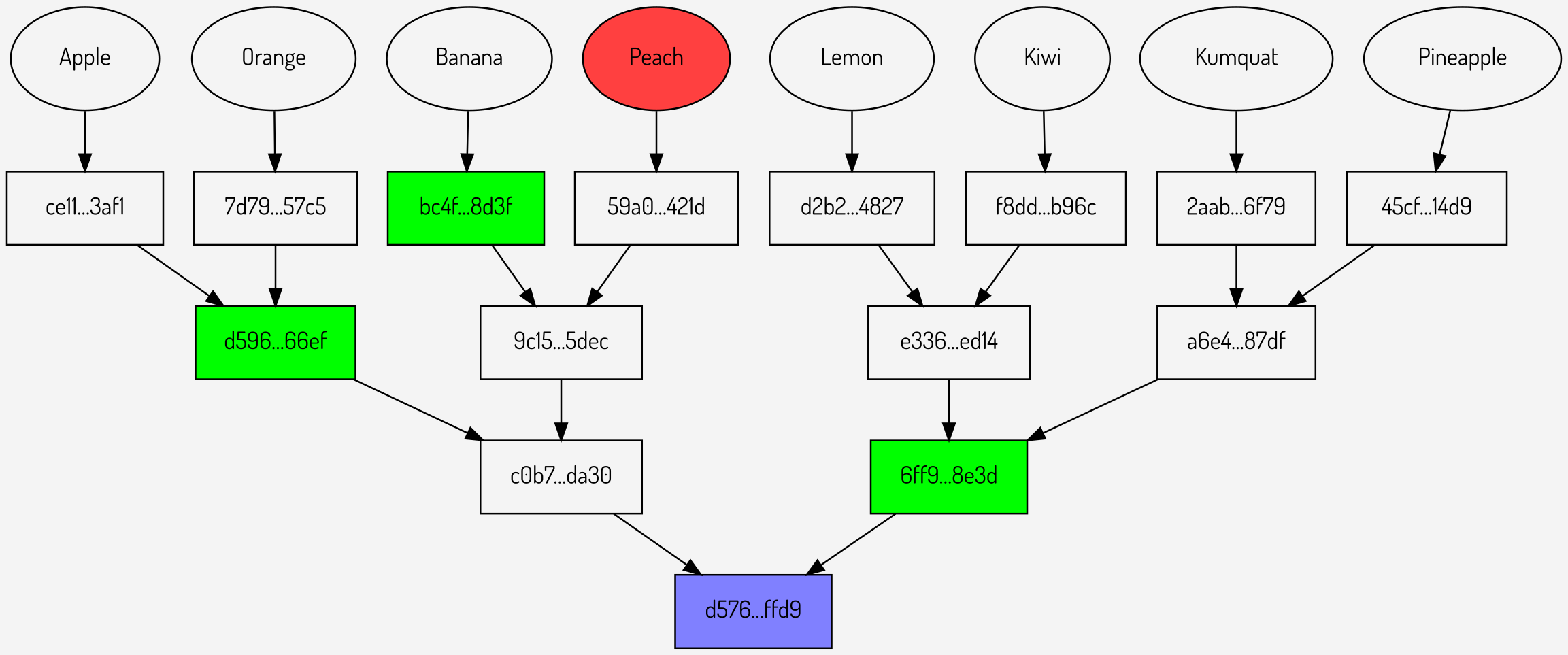
Figure 5: A Merkle proof
A Merkle proof requires three things: a value (shown in red), the intermediate hashes (shown in green) and the Merkle root (shown in blue). For each value there will be a different set of intermediate hashes.
Merkle proofs are commonly used in blockchains to show that a value is in a set without requiring the entire set to be stored on the blockchain. For example, an Ethereum token contract might have a whitelist feature to allow select accounts to purchase tokens. Rather than store every whitelisted account on the blockchain, which would be prohibitively expensive if there are many thousands of accounts on the whitelist, a Merkle tree of the accounts can be created and just the root stored on the blockchain.
For example, if the root is stored in a smart contract it becomes easy for the contract to prove an account is on the whitelist: an account supplies the intermediate hashes (provided in some off-chain manner by the contract owner to the account holder) and the smart contract hashes the account with the intermediate hashes in order. If the result matches the Merkle root it knows the account is on the whitelist.
Note the relationship between the hashes in the Merkle path and the hashes in the proof shown in the last two diagrams: each hash in the proof is the sibling of the hash in the path at the same level in the tree. This shows graphically that the proof gives the ability to recreate the path for the value, which is why the end result will be the Merkle root.
As can be seen above some benefits of using Merkle proofs are:
- the on-chain storage required is far smaller than if storing values
- the full set of values are not exposed by storing them publicly on-chain
- the cost of confirming the presence of a specific value in the set of values by confirming a proof can be lower (faster and cheaper) than checking against the set
Repeated proofs
In the above example each account only sends in the single proof required to verify they are on the whitelist. An alternative use of Merkle trees is as part of probabilistic proofs of knowledge (commonly known as STARKs), where each proof increases the likelihood that the creator of the Merkle tree (known as the prover) knows all of the values that make up the tree. In this situation the prover often generates hundreds of proofs against a single Merkle tree containing tens or even hundreds of thousands of values. The Merkle root and proofs are sent together to a verifier to confirm their validity.
Examining repeated proofs in the context of our original example, below are three proofs against the same tree:
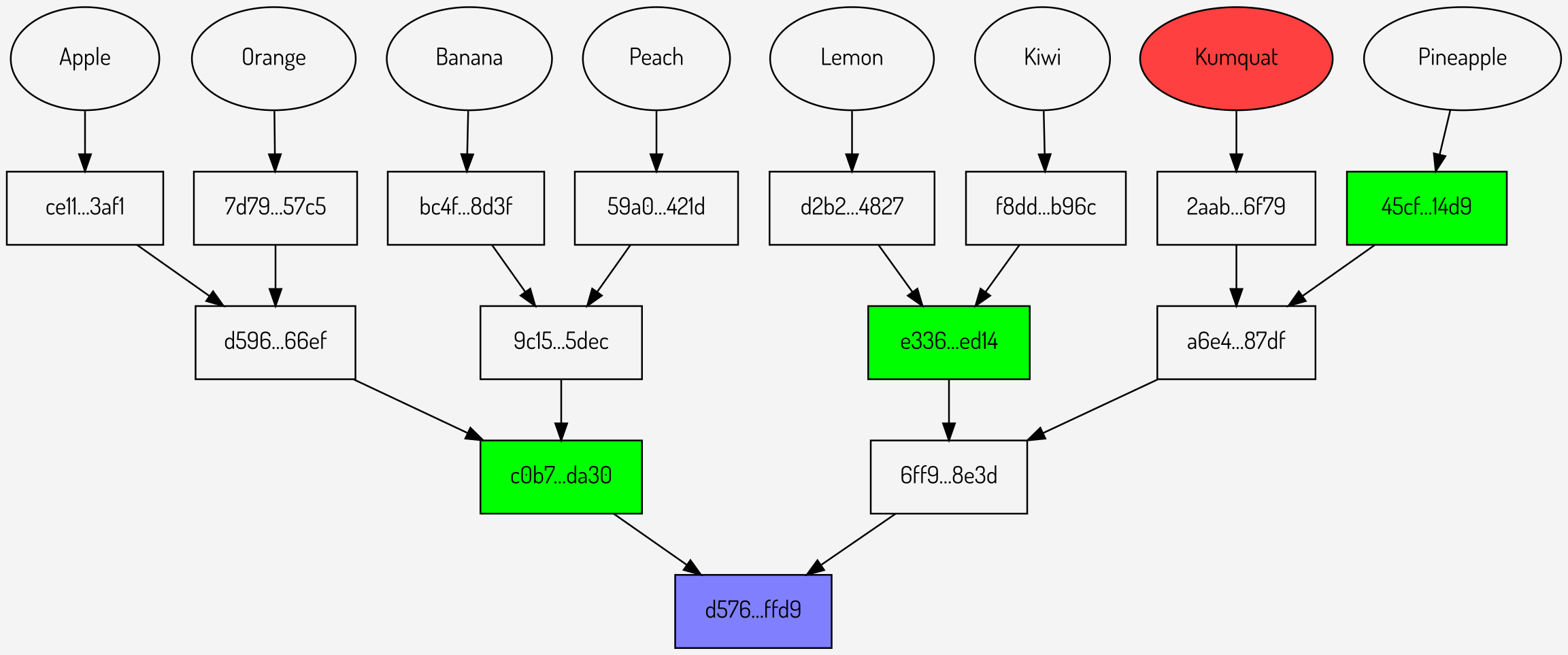
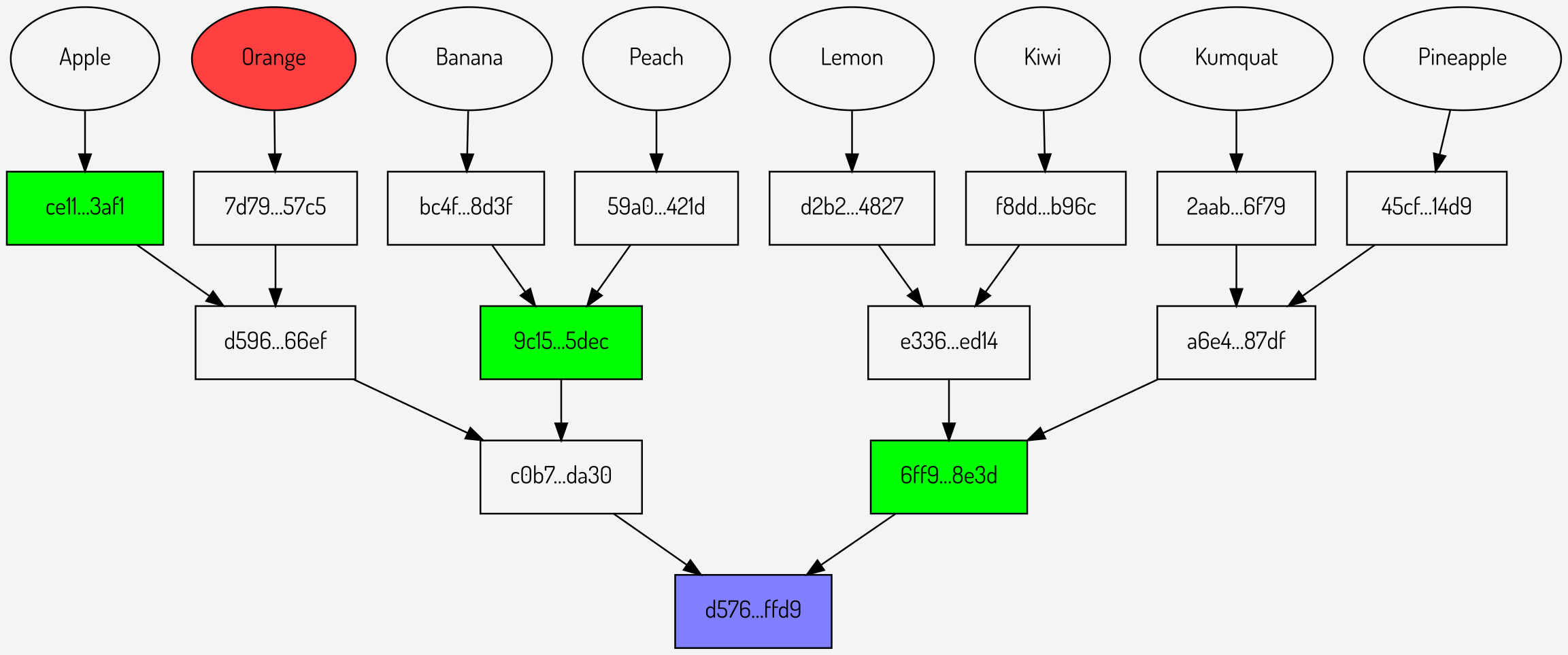
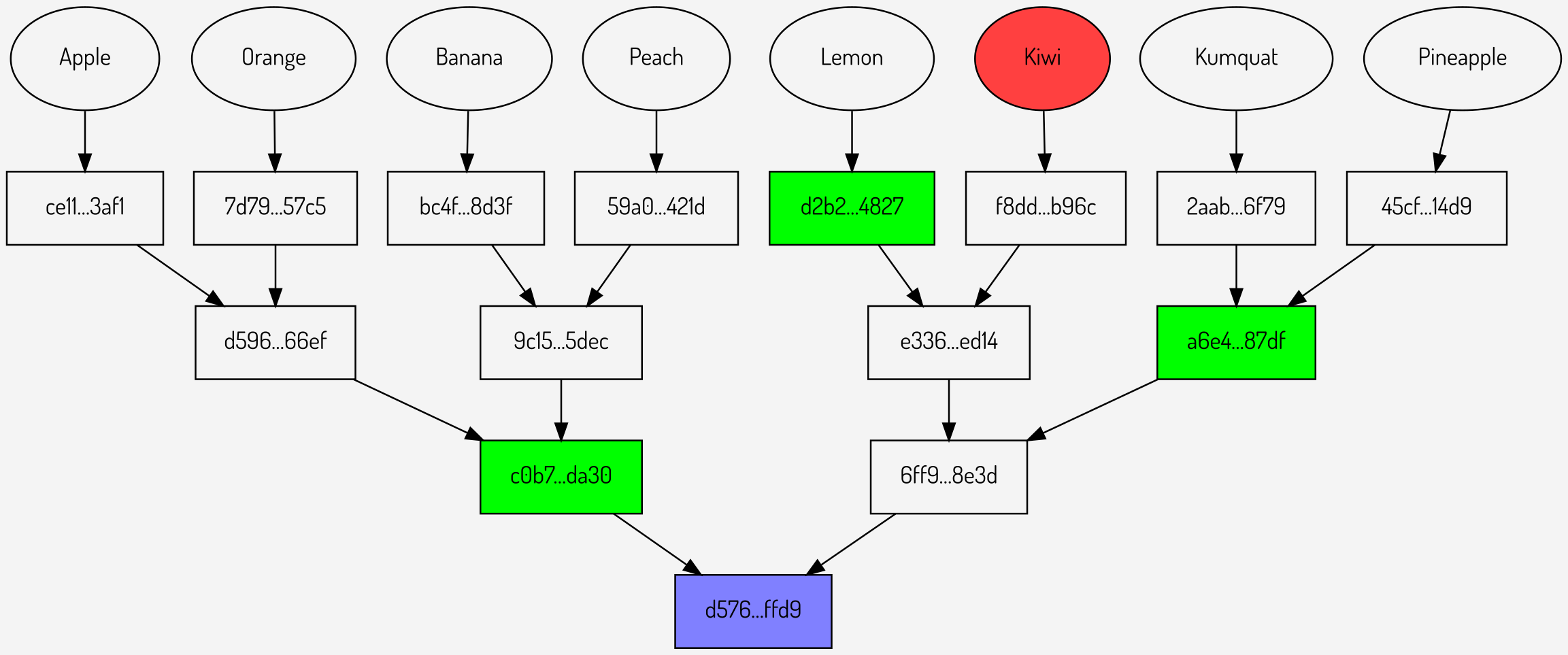
Figures 6,7,8: Repeated proofs using the same Merkle root
It can be seen that in total sending the Merkle root (once) plus the proofs involves sending 10 hashes: one for the root and three for each of the proofs.
Can this be more efficient? It can be seen that at the first level of the tree, where there are only two values \(c0b7…da30\) and \(6ff9…8e3d\), the proofs are sending a total of three hashes (one per proof). What if the Merkle root was extended to provide not just the lowest level but also the next level up?
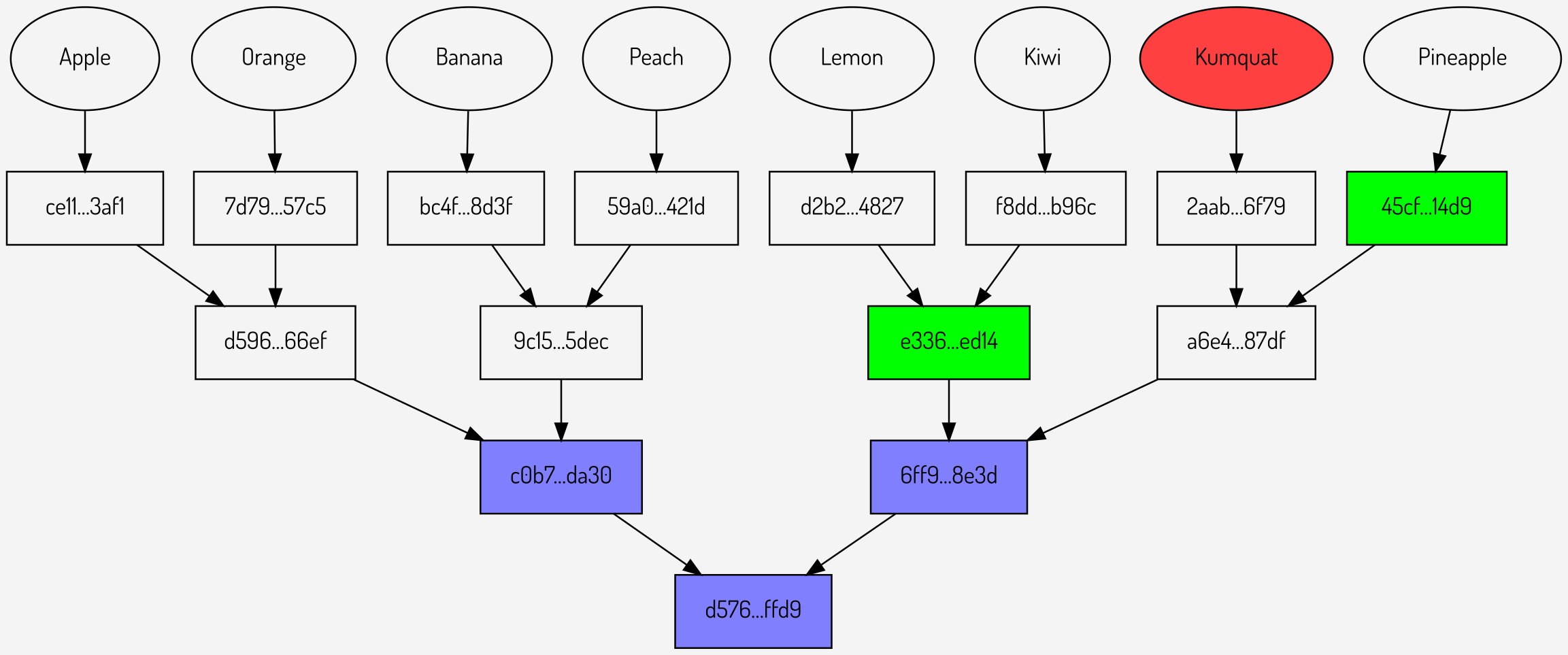
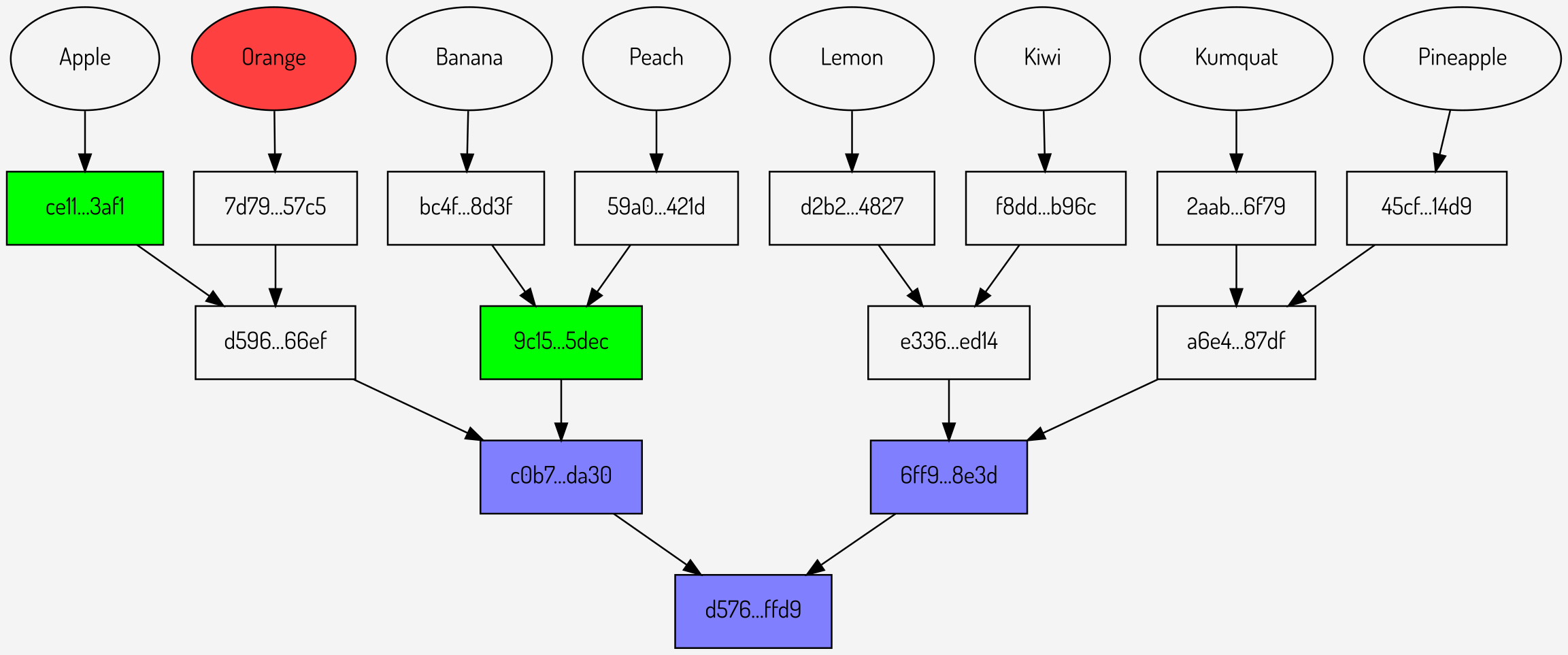
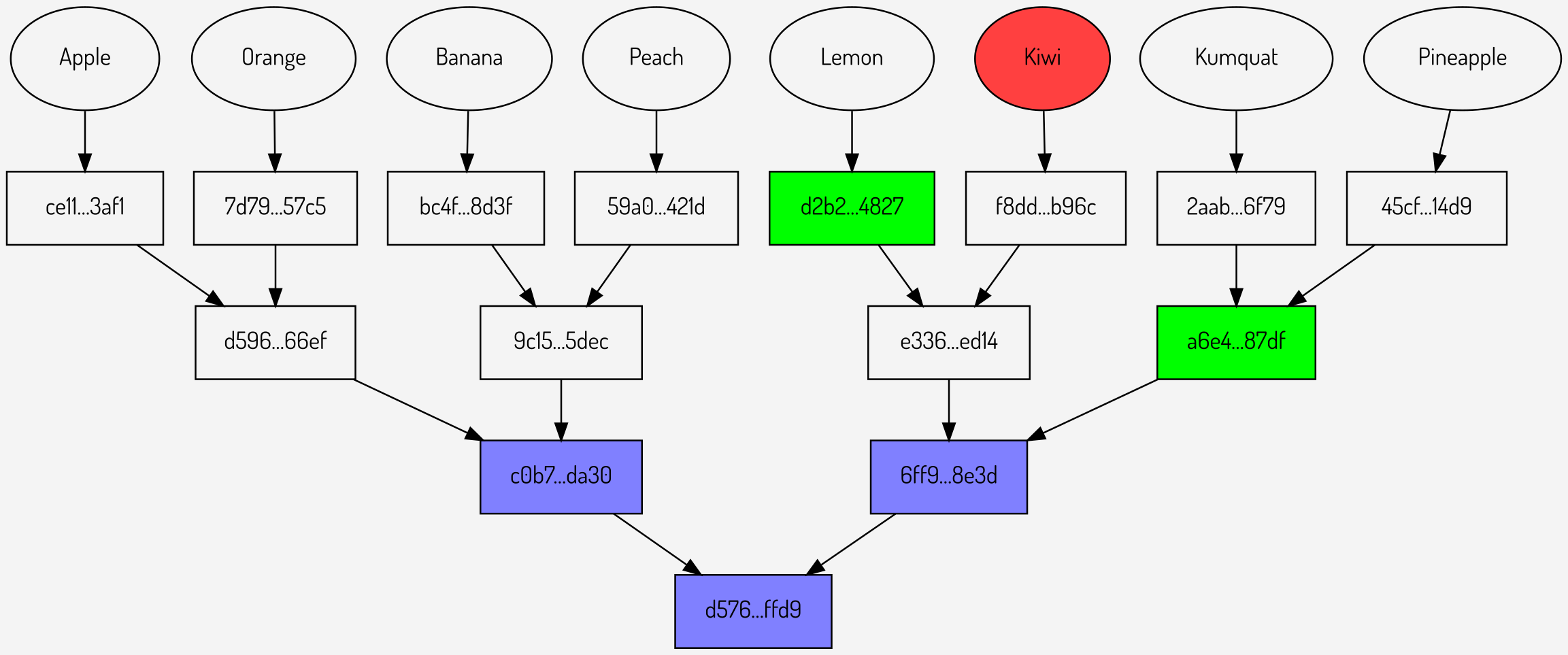
Figures 9,10,11: Repeated proofs using an extended Merkle root
It can be seen that in total sending the extended Merkle root (once) plus the proofs now involves sending 9 hashes: three for the root and two for each of the proofs. Although this reduction appears small it increases significantly as the number of proofs increases.
Merkle pollards
We call an extended Merkle root a Merkle pollard. It is defined as the Merkle root plus a number of levels of intermediate branches. The order of a Merkle pollard is the number of branches above the root that form the pollard (an order 0 Merkle pollard of a tree is equivalent to the root). An order 1 Merkle pollard contains one level of intermediate branches, as shown below:

Figure 12: An order 1 Merkle pollard
An order 2 Merkle pollard contains two levels of intermediate branches, as shown below:
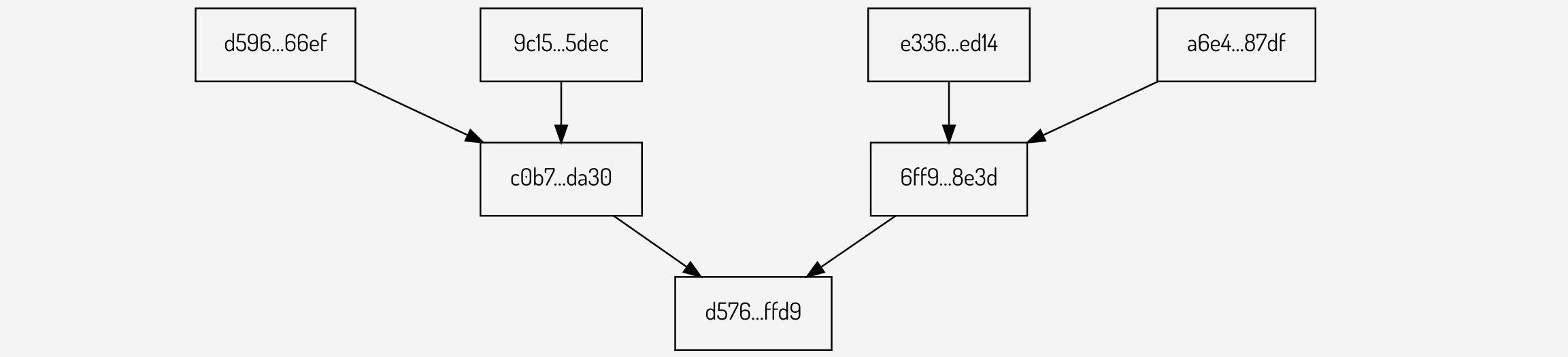
Figure 13: An order 2 Merkle pollard
In situations where there are many repeated proofs against the same Merkle tree, using a Merkle pollard decreases both the size of the proof (as there are fewer hashes per proof) and time taken to verify the proof (as there are fewer hashes needed to be calculated per verification). The mathematics for calculating the optimal order of a Merkle pollard is simply the floor of the base 2 logarithm of the number of proofs. A table of lower orders, along with the resultant space and time saving for an example tree with 4,096 values, are shown below:
| Proofs | Pollard order | Saving |
|---|---|---|
| 1 | 0 | 0% |
| 2-3 | 1 | 0-3% |
| 4-7 | 2 | 4-9% |
| 8-15 | 3 | 10-17% |
| 16-31 | 4 | 18-25% |
| 32-63 | 5 | 25-33% |
| 64-127 | 6 | 34-42% |
| 128-255 | 7 | 42-50% |
The savings for using Merkle pollards can quickly mount up. For example, a test STARK proof using Merkle roots at 564KB was reduced using Merkle pollards to 346KB, a reduction of 40%. Reductions were also seen in the time taken to transmit and verify the proof.
Sample implementation
An implementation of a Merkle tree with pollards for the Go language can be found at https://github.com/wealdtech/go-merkletree⧉ .
Sparse Merkle multiproofs
Sparse Merkle multiproofs are an alternative to pollarding that provide space-efficient proofs for multiple values in the same Merkle tree. Sparse Merkle multiproofs have different restrictions and requirements to Merkle pollards, and are examined in detail in a separate article⧉ .